


This article endeavors to explain high speed microservices. If you are unfamiliar with the term microservices, you may want to first read this blog post on microservices by Michael Brunton and if have more time on your hands this one by James Lewis and Martin Fowler.
High speed microservices is a philosophy and set of patterns for building services that can readily back mobile and web applications at scale. It uses a scale up and out versus a scale out model to do more with less hardware. A scale up model uses in-memory operational data, efficient queue hand-off, and async calls to handle more calls on a single node.
In general the cloud scale out model, employs a sense of reckless abandon. If your app has performance issues, no problem spin up 100 servers. Still not fast enough. Try 1000 servers. This has a cost. This does not replace a cloud scale out model per se. It just makes a cloud scale out model more cost effective. Do more with less.
In general the cloud scale out model, employs a sense of reckless abandon. If your app has performance issues, no problem spin up 100 servers. Still not fast enough. Try 1000 servers. This has a cost. This does not replace a cloud scale out model per se. It just makes a cloud scale out model more cost effective. Do more with less.
This is not to say that there are not advantages to the cloud scale out model. This is to say that an ability to do more with less hardware has cost savings, and you can still scale out as needed in the cloud.
The beauty of high-speed microservices is it gets back to OOP roots where data and logic live together in a cohesive understandable representation of the problem domain, and away from separation of data and logic. Since data lives with the service logic that operates on it. Also less time is spent dealing with cache coherency issues as the services own or lease the data (own for a period of time). The code tends to be smaller to do the same things.
You can expect to write less code. You can expect the code you write to run faster. To a true developer and software engineer this is a boon. Algorithm speed matters again. It is not dust on the scale while you wait for a response from the database. This movement frees you to do more in less time and to have code that runs orders of magnitudes faster than typical IO bound, cloud lemming services.
There are many frameworks that you can use to build a high speed microservice system. Vertx, Akka, Kaftka, Redis, Netty, Node.js, Go Channels, Twisted, QBit Java Microservice Lib, etc. are all great technology stacks to build these types of services. This article is not about any particular technology stack or programming language but a more abstract coverage of what it means to build these type of high speed services devoid of language or technology stack preference.
The model described in this article is the inverse of how many applications are built. It is not uncommon to need 3 to 20 servers for a service where in a traditional system you might need 100s or even 1,000s. Your EC2 bill could be cut into 1/10th the cost for example. This is not just supposition but actual observation.
In this model, you typically add extra services to enable fail over support not to scale out per se. You will reduce the amount of servers needed and your code base will be more coherent if you adopt these strategies.
You may have heard, keep your services stateless. We are recommending the opposite. Make your services own their operational data.
Attributes of High speed services
High speed services have the following attributes:
- High speed services are in-memory services
- High speed services do not block
- High speed services own their data
- Scale out involves sharding services
- Reliability is achieved by replicating service stores
An in-memory service is a service that runs in-memory. An in-memory services is non-blocking. An in-memory service can load its data from a central data store.
In-memory services can load data it owns asynchronously and does not block. It continues to service other requests while the data is loading.
At first blush it appears that an in-memory service can achieve its in-memory from using a cache. This is not the case. An in-memory service can use caches but and in-memory service owns its core data. Cached data is only from other services that own their data.
Single writer rule: Only one service at any point in time can edit service particular set of service data
In-memory services either own their data or own their data for a period of time. Owning the data for a period of time is a lease model.
Think of it this way. Data can only be written to by one service at any give point in time. Cache inconsistencies and cache control logic is the root of all evil. The best way to keep data in sync with caches is to never use caches or use them sparingly. It is better to use a service stores that can keep up with your application vending the data as needed in a lease model. Or to create longer leases on service data to improve speed. More on leasing and service stores is described later.
Avoid the following:
- Caching (use sparingly)
- Clustering
- Blocking
- Transactions
- Databases for operational data
Embrace the following:
- In-memory service data and data faulting
- Sharding
- Async callbacks
- Replication / Batching / Remediations
- Service Stores for operational data
Data faulting and data leasing seem a lot like caching. The key difference is ownership of data and the single writer principle.
Imagine a mobile app with a set of services that contains user data. The first call to any service checks to see if that users data is already loaded in the service. If the user data is not loaded into the service than the call from the mobile app is put into a queue and the call waits for the user data to get loaded asynchronously. The service continues to handle other calls and the service gets notified when the user data loads, and executes the call on the user data load event then. Since we can get many calls to load user data in a given second, we do not load each user one at a time but we load 100 user at a time or 1000 users at a time or we batch load all requests every 50ms (or both) of all user requests in that time. Loading the user data when it needed is called data faulting. Loading 1000 users at a time or all users in the last 50ms or all users since the last user load is called batching request. Batching requests is combining many requests into a single message to optimize IO throughput. Data faulting is the same way your OS loads disk segments into memory pages for virtual memory.
High speed services employ the following:
- Timed/Size Batching
- Callbacks
- Call interception to enable data faulting from the service store
- Data faulting for elasticity
Data ownership
The more data you can have in-memory the faster your services can run. Not all use cases and data fit this model. Some exceptions can be made. The more important principle is data ownership. This principle comes from the canonical definition of microservices.
In-memory is a means to an end. Mostly to facilitate non-blocking. The more important point is to have the service own the data instead of just being a view into shared data. The more important principle is the single writer principle and the avoidance of cache.
In-memory is a means to an end. Mostly to facilitate non-blocking. The more important point is to have the service own the data instead of just being a view into shared data. The more important principle is the single writer principle and the avoidance of cache.
Let's say that some data is historical data, and historical data rarely gets edited, but it does get edited. Then in this scenario it might make no sense at all to not load the historical data from a database and then update the database directly and skip the service store altogether since the usage is rare and unlikely to hamper the overall performance of the system.
If size of the data is an issue remember that you can shard the services and you can also fault data into a service server in batches. These two vectors should allow most if not all of the operational data to be loaded into memory and enable the single writer principle. Think of this as more of the Pareto principle. You don't need all. You just need the set of data in-memory that is going to give you the SLA that you need. All would be nice. But you can only have 20% of the data that is faulted in and still have a really fast system.
A lease can be 1/2 hour, 8 hours, or some other period of time. Once the lease has expired which could be based on the last time that service data was used, then the data just waits in the service store.
A lease can be 1/2 hour, 8 hours, or some other period of time. Once the lease has expired which could be based on the last time that service data was used, then the data just waits in the service store.
Why Lease? Why not just own?
Why not just own data out right. Well you can if the service data is small enough. Leasing data provides a level of elasticity. This allows you to spin up more nodes. If you optimize and tune the data load from the service store to the service then loading users data becomes trivial and very performant. The faster and more trivial the data fault loading, the shorter you can lease the data and the more elastic your services are. In like manner services can save data periodically to the service store or even keep data in a fault tolerant local store (store and forward) and update the service store in batches to accommodate speed and throughput. Leasing data is not the same as getting data from the cache. In the lease model only one node can edit the data at any given time.
Service Sharding / Service Routing
Elasticity is achieved through leasing and sharding. A service server node owns service data for a period of time. All calls for that users data is made to that server. In front of a series of service servers is a service router. A service router could be an F5 (network load balancer) that maintains server/user affinity through an HTTP header. A service router could be a more complex entity that knows more about the problem domain and knows how to route calls to other back end services.
Fault tolerance
The more important the data and the more replication and synchronization that needs to be done. The more important the data the more resources that are needed to ensure data safety.
If a service node goes down, a service router can select another service node to do that work. The service data will be loaded in an async/data faulting/batch. If the service was sending updates to changes then no state is lost except the state that was not sent to the service store since the last update. The more important the state/data, the more synchronization that should be done when the data is modified. For example, the service store can send an async confirmation of a save, the service could enqueue a response to the client. The client or service tier could opt to add retry logic if it does not get a response from the server. You can also replicate calls to services. You can also create a local store and forward for important calls.
Service Store
The primary store for a high speed service system is a service store. A service store can treat the service data as opaque. A service store is not a database. A service store is not a cache either. A service store may also keep the data in-memory. The primary function of a service store is vending data quickly to services that are faulting data in.
A services store also takes care of data replication for data safety and safe storage. A service store should be able to bulk save data and bulk load data to/from a service and to/from replicas. A service store like the service itself should never block. Responses are sent asynchronously. WebSocket or sockets is a great mechanism to send responses from a service store to a given number of services. JSON or some form of binary JSON is a good transport and storage mechanism for a service store.
Service stores are elastic and typically sharded but not as elastic as service servers. Service stores employ replication and synchronization to limit data loss. Service stores are special servers so the rest of your application can be elastic and more fault tolerant. It is typical to over provision service stores to allow for a particular span of growth. Adding new nodes and setting up replication is more deliberate than it is with services. The service store and the leasing model is what enables the services to be elastic.
By special servers, we mean service store servers might use special hardware like disk level replication and servers which might employ additional monitoring. All service data saved to a service store should be saved in at least two servers. There is a certain level of replication that is expected. Service stores may also keep a transaction log so that others processes can follow the log and update databases for querying and reporting.
In high-speed services, databases are only for reporting, long term storage, backup, etc. All operational data is kept and vended out of the service stores which maintain their own replication and backups for recovery. All modifications to data is done by services. Service stores typically use JSON or some other standard data format for long term storage for both the transaction logs for storage into secondary databases.
A service store is the polar opposite of Big Data. A service store is just operational data. One could tail the transaction logs to create Big Data.
Active Objects / Threading model:
To minimize complex synchronization code that can become a bottle neck one should employ some form of Active Objects pattern for stateful, high-speed services. One could use an event bus system like Vertx or Node.js or an Actor system like Akka or GO channels or Python Twisted and build their own Active Object service system.
The active object pattern separates method execution from method invocation for objects that each reside in their own thread of control (or in the case of QBit for a group of objects that are in the same thread of control).
The goal of Active Objects is to introduce concurrency, by using asynchronous method invocation and a scheduler for handling requests. The scheduler could be a resumable thread draining a queue of method calls. This scheduler could also check to see if data needed for this call was already loaded into the system and fault data in from the service store into the running service before the call is made.
The Active Object pattern consists of six elements:
- A client proxy to provide an interface for clients. The client proxy can be local (local client proxy) or remote (remote client proxy).
- An interface which defines the method request on an active object.
- A queue of pending method requests from clients.
- A scheduler, which decides which request to execute next which could for example delay invocation until service data if faulted in or which could reorder method calls based on priority or which could work with several related services from one scheduler allowing said services to make local non-enqueued calls to each other.
- The implementation of the active object methods. Contains your code.
- A service callback for the client to receive the result.
Developing high-speed microservices (tools needed)
IN PROGRESS
Docker, Rocket, Vagrant, EC2, boto, Chef, Puppet, testing, perf testing. (TBD)
Service discovery and health
IN PROGRESS
Consul, etcd, Zookeeper, Nagios, Sensu, SmartStack, Serf, DNS, (TBD)
Similarities to plain microservices
IN PROGRESS
Data ownership, standalone process, container which has all parts needed, docker is the new war file, etc.
What makes high speed microservices different from plain microservices
IN PROGRESS
Async, Non-blocking, more focus on data ownership and data faulting
Glossary:
Service Store : Sharded fault tolerant opaque storage of service data. The service store enables services to be elastic.
Service Server : A server that hosts one or more services.
High Speed Service: An in-memory high speed service that is non-blocking that owns its service data.
Database: Something that does reporting or long term backups for a high speed service system. A database never holds operational data (there is an uncommon exception to this rule beyond the scope of this article).
Service Router: The first tier of servers which decide where to route calls to which services based on sharding rules which can be simple or complex. Simple rules could be handled by ha_proxy or an F5. Complex rules can be handled by service routing tier.
Rick Hightower, the author of this blog post is the primary author of QBit and Boon. Boon is a very fast JSON parser, string parsing, and reflection lib. QBit is a fast in-memory service queue lib that employs Actor-like Active Objects.
200 M message in-proc per second, 1 M RPC calls per second = QBit
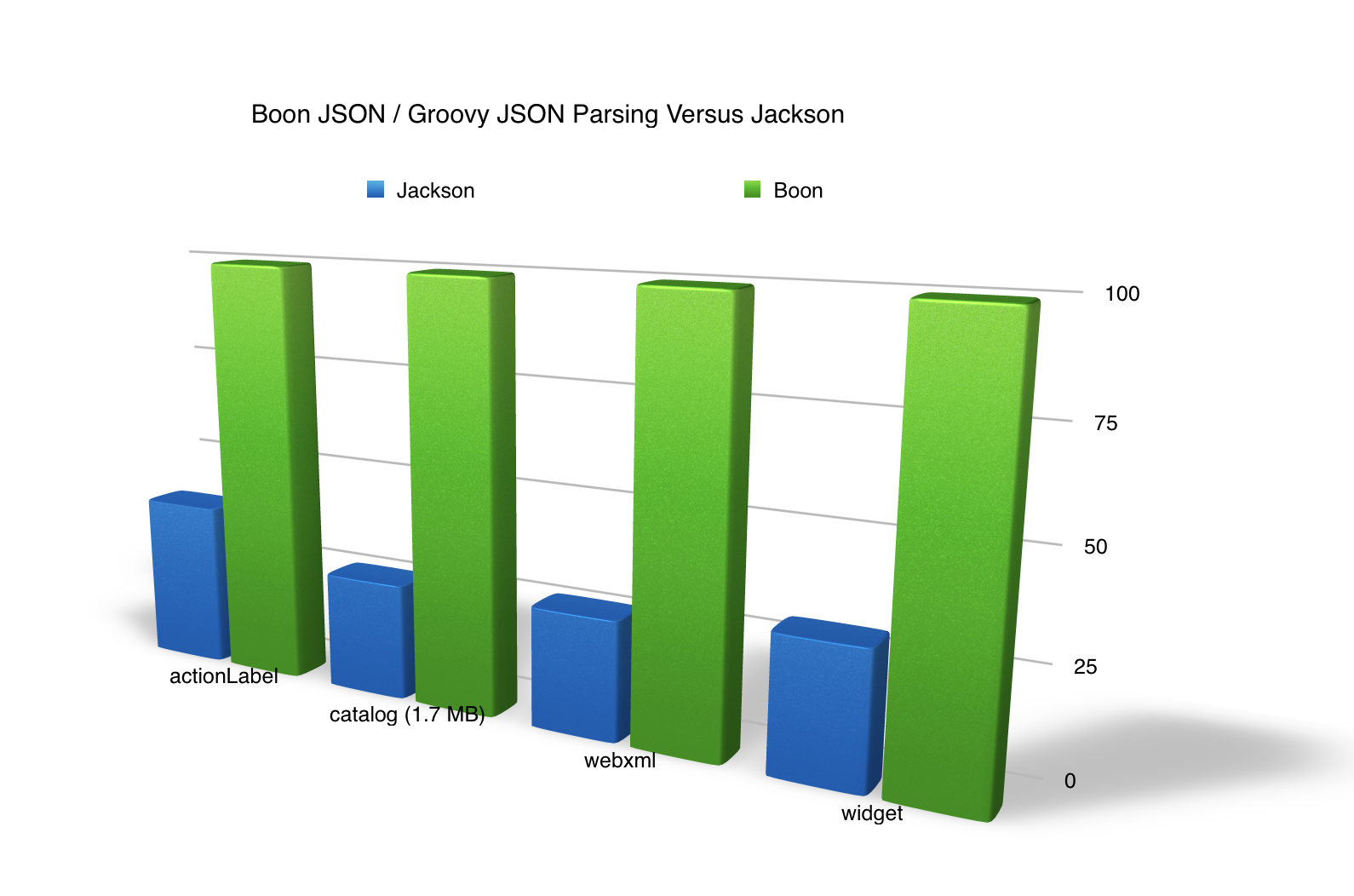
The above shows the high-speed nature of Boon and QBit.
I put them there to pique your interest.
QBit is a lot more than just raw speed.
Learn more about QBit:
[Detailed Tutorial] QBit microservice example
I am not just a commentator. I have worked with etcd. Wrote a Java client for it. I have used this techniques in production settings. I also wrote a high-speed JSON parser that uses an index overlay that is geared towards REST/WebSocket microservice development.
I also tried to put quite a bit of what I have learned into Boon and QBit.
Here is more information about QBit.
qbit - The Microservice Lib for Java - JSON, REST, WebSocket, Speed! 

Got a question? Ask here: QBit Google Group.
Everything is a queue. You have a choice. You can embrace it and control it. You can optimize for it. Or you can hide behind abstractions. QBit opens you up to peeking into what is going on, and allows you to pull some levers without selling your soul.
QBit is a library not a framework. You can mix and match QBit with Spring, Guice, etc.
QBit is FAST!
Status
Lot's of progress. More people are helping out. QBit now works with Vertx (standalone or embedded), Jetty (standalone) or just plain Java Servlets.
License
Apache 2
Java Microservice Lib
QBit has inproc services, REST microservices and WebSocket microservices as well as an in-proc service event bus (which can be per module or per app). It supports workers and in-memory services.
Before we describe more, here are two sample services:
Todo Service
@RequestMapping("/todo-service")
public class TodoService {
@RequestMapping("/todo/count")
public int size() {...
@RequestMapping("/todo/")
public List<TodoItem> list() {...
Adder Service using URI params
@RequestMapping("/adder-service")
public class AdderService {
@RequestMapping("/add/{0}/{1}")
public int add(@PathVariable int a, @PathVariable int b) {...
}
QBit philosophy:
At the end of the day QBit is a simple library not a framework. Your app is not a QBit app but a Java app that uses the QBit lib. QBit allows you to work with Java UTIL concurrent, and does not endeavor to hide it from you. Just trying to take the sting out of it.
Does it work
We have used techniques in Boon and QBit with great success in high-end, high-performance, high-scalable apps. We helped clients handle 10x the load with 1/10th the servers of their competitors using techniques in QBit. QBit is us being sick of hand tuning queue access and threads.
Boon and QBit humility policy
Ideas for Boon and QBit often come from all over the web. We make mistakes. Point them out. As a developer of Boon and QBit, we are fellow travelers. If you have an idea or technique you want to share, we listen.
Inspiration
A big inspiration for Boon/QBit was Akka, Go Channels, Active Objects, Apartment Model Threading, Actor, and the Mechnical Sympathy papers.
"I have read the AKKA in Action Book. It was inspiring, but not the only inspiration for QBit.". "I have written apps where I promised a lot of performance and the techniques from QBit is how I got it."
- Rick Hightower
QBit has ideas that are similar to many frameworks. We are all reading the same papers. QBit got inspiration from the LMAX disruptor papers and this blog post about link transfer queue versus disruptor. We had some theories about queues that blog post insprired us to try them out. Some of these theories are deployed at some of the biggest middleware backends and whose name brands are known around the world. And thus QBit was born.
QBit also took an lot of inspiration by the great work done by Tim Fox on Vertx. The first project using something that could actually be called QBit (albeit early QBit) was using Vertx on an web/mobile microserivce for an app that could potentially have 80 million users. It was this experience with Vertx and early QBit that led to QBit development and evolution. QBit is built on the shoulders of giants.
Does QBit compete with...
Spring Disruptor: No. You could use QBit to write plugins for Spring Disruptor I suppose, but QBit does not compete with Spring Disruptor. Spring Boot/Spring MVC: No. We use the same annotations but QBit is geared for high-speed in-memory microservices. It is more like Akka than Spring Boot. QBit has a subset of the features of Spring MVC geared only for microservices, i.e., WebSocket RPC, REST, JSON marshaling, etc. Akka: No. Well Maybe. Akka has similar concepts but they take a different approach. QBit is more focused on Java, and microservices (REST, JSON, WebSocket) than Akka. LMAX Disruptor: No. In fact, we can use disruptor as on of the queues that QBit uses underneath the covers.
(Early benchmarks have been removed. They were here. QBit got a lot faster. Benchmarking QBit is a moving target at the moment. Links and reports will be created.)
Code Examples
Basic Queue example (REST style services is further down)
BasicQueue<Integer> queue = BasicQueue.create(Integer.class, 1000);
//Sending threads
SendQueue<Integer> sendQueue = queue.sendQueue();
for (int index = 0; index < amount; index++) {
sendQueue.send(index);
}
sendQueue.flushSends();
...
sendQueue.sendAndFlush(code);
//other methods for sendQueue, writeBatch, writeMany
//Recieving Threads
ReceiveQueue<Integer> receiveQueue = queue.receiveQueue();
Integer item = receiveQueue.take();
//other methods poll(), pollWait(), readBatch(), readBatch(count)
What is QBit again?
QBit is a queuing library for microservices. It is similar to many other projects like Akka, Spring Reactor, etc. QBit is just a library not a platform. QBit has libraries to put a service behind a queue. You can use QBit queues directly or you can create a service. QBit services can be exposed by WebSocket, HTTP, HTTP pipeline, and other types of remoting. A service in QBit is a Java class whose methods are executed behind service queues. QBit implements apartment model threading and is similar to the Actor model or a better description would be Active Objects. QBit does not use a disruptor. It uses regular Java Queues. QBit can do north of 100 million ping pong calls per second which is an amazing speed (seen as high as 200M). QBit also supports calling services via REST, and WebSocket. QBit is microservices in the pure Web sense: JSON, HTTP, WebSocket, etc. QBit uses micro batching to push messages through the pipe (queue, IO, etc.) faster to reduce thread hand-off.
QBit lingo
QBit is a Java microservice lib supporting REST, JSON and WebSocket. It is written in Java but we could one day write a version in Rust or Go or C# (but that would require a large payday).
Service POJO (plain old Java object) behind a queue that can receive method calls via proxy calls or events (May have one thread managing events, method calls, and responses or two one for method calls and events and the other for responses so response handlers do not block service. One is faster unless responses block). Services can use Spring MVC style REST annotations to expose themselves to the outside world via REST and WebSocket.
ServiceBundle Many POJOs behind one response queue and many receive queues. There may be one thread for all responses or not. They also can be one receive queue.
Queue A thread managing a queue. It supports batching. It has events for empty, reachedLimit, startedBatch, idle. You can listen to these events from services that sit behind a queue. You don't have to use Services. You can use Queue's direct. In QBit, you have sender queues and receivers queues. They are separated to support micro-batching.
ServiceServer ServiceBundle that is exposed to REST and WebSocket communication.
EventBus EventBus is a way to send a lot of messages to services that may be loosely coupled.
ClientProxy ClientProxy is a way to invoke service through async interface, service can be inproc (same process) or remoted over WebSocket.
Non-blocking QBit is a non-blocking lib. You use CallBacks via Java 8 Lambdas. You can also send event messages and get replies. Messaging is built into the system so you can easily coordinate complex tasks. QBit takes an object-oriented approach to service development so services look like normal Java services that you already write, but the services live behind a queue/thread. This is not a new concept. Microsoft did this with DCOM/COM and called it active objects. Akka does it with actors and called them strongly typed Actors. The important concepts is that you get the speed of reactive and actor style messaging but you develop in a natural OOP approach. QBit is not the first. QBit is not the only.
Speed QBit is VERY fast. There is a of course a lot of room for improvement. But already 200M+ TPS inproc ping pong, 10M-20M+ TPS event bus, 500K TPS RPC calls over WebSocket/JSON, etc. More work needs to be done to improve speed, but now it is fast enough where we are focusing more on usability. The JSON support uses Boon by default which is up to 4x faster than other JSON parsers for the REST/JSON, WebSocket/JSON use case.
CURLable REST services example
Talk is cheap. Let's look at some code. You can get a detailed walk through in the Wiki. We have a lot of documentation already.
We will create a service that is exposed through REST/JSON.
To query the size of the todo list:
curl localhost:8080/services/todo-service/todo/count
To add a new TODO item.
curl -X POST -H "Content-Type: application/json" -d \
'{"name":"xyz","description":"xyz"}' \
http://localhost:8080/services/todo-service/todo
To get a list of TODO items
curl http://localhost:8080/services/todo-service/todo/
The TODO example will use and track Todo items.
Todo item POJO sans getter
package io.advantageous.qbit.examples;
import java.util.Date;
public class TodoItem {
private final String description;
private final String name;
private final Date due;
The TodoService uses Spring MVC style annotations.
Todo Service
@RequestMapping("/todo-service")
public class TodoService {
private List<TodoItem> todoItemList = new ArrayList<>();
@RequestMapping("/todo/count")
public int size() {
return todoItemList.size();
}
@RequestMapping("/todo/")
public List<TodoItem> list() {
return todoItemList;
}
@RequestMapping(value = "/todo", method = RequestMethod.POST)
public void add(TodoItem item) {
todoItemList.add(item);
}
}
Side note Why Spring style annotations?
Why did we pick Spring style annotations? 1) Spring is not a standard and neither is QBit. 2) We found the Spring annotations to be less verbose. 3) More people use Spring than Java EE. We wrote QBit for people to use. We could easily support JAX-RS style annotations, and we probably will. Since QBit focuses on JSON, we do not need all of the complexity of JAX-RS or even all the features of the Spring MVC annotations. Also we can literally use the actual Spring annotations. QBit and Boon use a non-type safe mechanism for annotations which means they are not tied to a particular lib. You can define your own. We hate vendor tie-in even if it is an open source vendor.
Now just start it up.
public static void main(String... args) {
ServiceServer server = new ServiceServerBuilder().build();
server.initServices(new TodoService());
server.start();
}
That is it. There is also out of the box WebSocket support with client side proxy generation so you can call into services at the rate of millions of calls per second.
Using URI Params for QBit microservice
@RequestMapping("/adder-service")
public class AdderService {
@RequestMapping("/add/{0}/{1}")
public int add(@PathVariable int a, @PathVariable int b) {
return a + b;
}
}
WebSocket
You can always invoke QBit services via a WebSocket proxy. The advantage of a WebSocket proxy is it allows you execute 1M RPC+ a second (1 million remote calls every second).
Using a microservice remotely with WebSocket
/* Start QBit client for WebSocket calls. */
final Client client = clientBuilder()
.setPort(7000).setRequestBatchSize(1).build();
/* Create a proxy to the service. */
final AdderServiceClientInterface adderService =
client.createProxy(AdderServiceClientInterface.class,
"adder-service");
client.start();
/* Call the service */
adderService.add(System.out::println, 1, 2);
The output is 3.
3
The above uses a WebSocket proxy interface to call the service async.
interface AdderServiceClientInterface {
void add(Callback<Integer> callback, int a, int b);
}
REST call with URI params
The last client example uses WebSocket. You could also just use REST, and actually use the URI params that we setup. REST is nice but it is going to be slower than WebSocket support.
QBit ships with a nice little HTTP client. We can use it.
You can use it to send async calls and WebSocket messages with the HTTP client.
Here we will use the http client to invoke our remote method:
Using a microservice remotely with REST QBit microservice client
HttpClient httpClient = httpClientBuilder()
.setHost("localhost")
.setPort(7000).build();
httpClient.start();
String results = httpClient
.get("/services/adder-service/add/2/2").body();
System.out.println(results);
The output is 4.
4
Accessing The URI Param example with CURL
You can also access the service from curl.
$ curl http://localhost:7000/services/adder-service/add/2/2
See this full example here: QBit microservice getting started tutorial.
Working with WebSocket, HttpClient etc.
QBit has a library for working with and writing async microservices that is lightweight and fun to use.
WebSocket server and client.
Create an HTTP server
/* Create an HTTP server. */
HttpServer httpServer = httpServerBuilder()
.setPort(8080).build();
Setup server WebSocket support
/* Setup WebSocket Server support. */
httpServer.setWebSocketOnOpenConsumer(webSocket -> {
webSocket.setTextMessageConsumer(message -> {
webSocket.sendText("ECHO " + message);
});
});
Start the server
/* Start the server. */
httpServer.start();
Setup the WebSocket client
/** CLIENT. */
/* Setup an httpClient. */
HttpClient httpClient = httpClientBuilder()
.setHost("localhost").setPort(8080).build();
httpClient.start();
Client WebSocket
/* Setup the client websocket. */
WebSocket webSocket = httpClient
.createWebSocket("/websocket/rocket");
/* Setup the text consumer. */
webSocket.setTextMessageConsumer(message -> {
System.out.println(message);
});
webSocket.openAndWait();
/* Send some messages. */
webSocket.sendText("Hi mom");
webSocket.sendText("Hello World!");
Output
ECHO Hi mom
ECHO Hello World!
Now stop the server and client. Pretty easy eh?
High-speed HTTP client and server done microservice style
Starting up an HTTP server
/* Create an HTTP server. */
HttpServer httpServer = httpServerBuilder()
.setPort(8080).build();
/* Setting up a request Consumer with Java 8 Lambda expression. */
httpServer.setHttpRequestConsumer(httpRequest -> {
Map<String, Object> results = new HashMap<>();
results.put("method", httpRequest.getMethod());
results.put("uri", httpRequest.getUri());
results.put("body", httpRequest.getBodyAsString());
results.put("headers", httpRequest.getHeaders());
results.put("params", httpRequest.getParams());
httpRequest.getReceiver()
.response(200, "application/json", Boon.toJson(results));
});
/* Start the server. */
httpServer.start();
The focus is on ease of use and using Java 8 Lambdas for callbacks so the code is tight and small.
Using HTTP Client lib
Now, let's try out our HTTP client.
Starting up an HTTP client
/* Setup an httpClient. */
HttpClient httpClient = httpClientBuilder()
.setHost("localhost").setPort(8080).build();
httpClient.start();
You just pass the URL, the port and then call start.
Synchronous HTTP calls
Now you can start sending HTTP requests.
No Param HTTP GET
/* Send no param get. */
HttpResponse httpResponse = httpClient.get( "/hello/mom" );
puts( httpResponse );
An HTTP response just contains the results from the server.
No Param HTTP Response
public interface HttpResponse {
MultiMap<String, String> headers();
int code();
String contentType();
String body();
}
There are helper methods for sync HTTP GET calls.
Helper methods for GET
/* Send one param get. */
httpResponse = httpClient.getWith1Param("/hello/singleParam",
"hi", "mom");
puts("single param", httpResponse );
/* Send two param get. */
httpResponse = httpClient.getWith2Params("/hello/twoParams",
"hi", "mom", "hello", "dad");
puts("two params", httpResponse );
...
/* Send five param get. */
httpResponse = httpClient.getWith5Params("/hello/5params",
"hi", "mom",
"hello", "dad",
"greetings", "kids",
"yo", "pets",
"hola", "neighbors");
puts("5 params", httpResponse );
The puts method is a helper method it does System.out.println more or less by the way.
The first five params are covered. Beyond five, you have to use the HttpBuilder.
/* Send six params with get. */
final HttpRequest httpRequest = httpRequestBuilder()
.addParam("hi", "mom")
.addParam("hello", "dad")
.addParam("greetings", "kids")
.addParam("yo", "pets")
.addParam("hola", "pets")
.addParam("salutations", "all").build();
httpResponse = httpClient.sendRequestAndWait(httpRequest);
puts("6 params", httpResponse );
Http Async HTTP Client
There are async calls for GET as well.
Async calls for HTTP GET using Java 8 lambda
/* Using Async support with lambda. */
httpClient.getAsync("/hi/async", (code, contentType, body) -> {
puts("Async text with lambda", body);
});
Sys.sleep(100);
/* Using Async support with lambda. */
httpClient.getAsyncWith1Param("/hi/async", "hi", "mom", (code, contentType, body) -> {
puts("Async text with lambda 1 param\n", body);
});
Sys.sleep(100);
/* Using Async support with lambda. */
httpClient.getAsyncWith2Params("/hi/async",
"p1", "v1",
"p2", "v2",
(code, contentType, body) -> {
puts("Async text with lambda 2 params\n", body);
});
Sys.sleep(100);
...
/* Using Async support with lambda. */
httpClient.getAsyncWith5Params("/hi/async",
"p1", "v1",
"p2", "v2",
"p3", "v3",
"p4", "v4",
"p5", "v5",
(code, contentType, body) -> {
puts("Async text with lambda 5 params\n", body);
});
Sys.sleep(100);
InProc QBit services
QBit allows for services behind queues to be run in-proc as well.
/* POJO service. */
final TodoManager todoManagerImpl = new TodoManager();
/*
Create the service which manages async calls to todoManagerImpl.
*/
final Service service = serviceBuilder()
.setServiceObject(todoManagerImpl)
.build().start();
/* Create Asynchronous proxy over Synchronous service. */
final TodoManagerClientInterface todoManager =
service.createProxy(TodoManagerClientInterface.class);
service.startCallBackHandler();
System.out.println("This is an async call");
/* Asynchronous method call. */
todoManager.add(new Todo("Call Mom", "Give Mom a call"));
AtomicInteger countTracker = new AtomicInteger();
//Hold count from async call to service... for testing and showing it is an async callback
System.out.println("This is an async call to count");
todoManager.count(count -> {
System.out.println("This lambda expression is the callback " + count);
countTracker.set(count);
});
todoManager.clientProxyFlush(); //Flush all methods. It batches calls.
Sys.sleep(100);
System.out.printf("This is the count back from the server %d\n", countTracker.get());
QBit Event Bus
QBit also has a service event bus. This example is a an employee benefits services example.
We have two channels.
public static final String NEW_HIRE_CHANNEL = "com.mycompnay.employee.new";
public static final String PAYROLL_ADJUSTMENT_CHANNEL = "com.mycompnay.employee.payroll";
An employee object looks like this:
public static class Employee {
final String firstName;
final int employeeId;
This example has three services: EmployeeHiringService, BenefitsService, and PayrollService.
These services are inproc services. QBit supports WebSocket, HTTP and REST remote services as well, but for now, let's focus on inproc services. If you understand inproc then you will understand remote.
The EmployeeHiringService actually fires off the events to other two services.
public class EmployeeHiringService {
public void hireEmployee(final Employee employee) {
int salary = 100;
System.out.printf("Hired employee %s\n", employee);
//Does stuff to hire employee
//Sends events
final EventManager eventManager =
serviceContext().eventManager();
eventManager.send(NEW_HIRE_CHANNEL, employee);
eventManager.sendArray(PAYROLL_ADJUSTMENT_CHANNEL,
employee, salary);
}
}
Notice that we call sendArray so we can send the employee and their salary. The listener for PAYROLL_ADJUSTMENT_CHANNEL will have to handle both an employee and an int that represents the new employees salary. You can also use event bus proxies so you do not have to call into the event bus at all.
The BenefitsService listens for new employees being hired so it can enroll them into the benefits system.
public static class BenefitsService {
@OnEvent(NEW_HIRE_CHANNEL)
public void enroll(final Employee employee) {
System.out.printf("Employee enrolled into benefits system employee %s %d\n",
employee.getFirstName(), employee.getEmployeeId());
}
Daddy needs to get paid.
public static class PayrollService {
@OnEvent(PAYROLL_ADJUSTMENT_CHANNEL)
public void addEmployeeToPayroll(final Employee employee, int salary) {
System.out.printf("Employee added to payroll %s %d %d\n",
employee.getFirstName(), employee.getEmployeeId(), salary);
}
}
The employee is the employee object from the EmployeeHiringService.
so you can get your benefits, and paid!
Find more details here:
Private event bus and event bus proxies
You can define your own interface to the event bus and you can use your own event buses with QBit. Each module in your service can have its own internal event bus.
To learn more read: QBit Microservice working with a private event bus and QBit Java Microservice lib using your own interface to the event bus.
Queue Callbacks
To really grasp QBit, one must grasp the concepts of a CallBack.
A CallBack is a way to get an async response in QBit.
You call a service method and it calls you back.
Client proxies can have callbacks:
Queue Callbacks - RecommendationService client interface
public interface RecommendationServiceClient {
void recommend(final Callback<List<Recommendation>> recommendationsCallback,
final String userName);
}
Callbacks are Java 8 Consumers with some optional extra error handling.
Queue Callbacks - Callback
public interface Callback <T> extends java.util.function.Consumer<T> {
default void onError(java.lang.Throwable error) { /* compiled code */ }
}
Services that can block should use callbacks. Thus if loadUser blocked in the following example, it should really use a callback instead of returning a value.
public class RecommendationService {
Queue Callbacks - Simple minded implementation of RecommendationService
private final SimpleCache<String, User> users =
new SimpleCache<>(10_000);
public List<Recommendation> recommend(final String userName) {
User user = users.get(userName);
if (user == null) {
user = loadUser(userName);
}
return runRulesEngineAgainstUser(user);
}
Let's pretend
loadUser has to look in a local cache, and if the user is not found, look in an off-heap cache and if not found it must ask for the user from the UserService which must check its caches and perhaps fallback to loading the user data from a database or from other services. In other words, loadUser can potentially block on IO.Queue Callbacks - The first rule of Queue Club - don't block
Our client does not block, but our service does. Going back to our
RecommendationService. If we get a lot of cache hits for user loads, perhaps the block will not be that long, but it will be there and every time we have to fault in a user, the whole system is gummed up. What we want to be able to do is if we can't handle the recommendation request, we go ahead and make an async call to the UserDataService. When that async callback comes back, then we handle that request. In the mean time, we handle recommendation lists requests as quickly as we can. We never block.
So let's revisit the service. The first thing we are going to do is make the service method take a callback. Before we do that, let's set down some rules.
The first rule of queue club don't block.
The second rule of queue club if you are not ready, use a callback and continue handling stuff you are ready for
Queue Callbacks - Adding a CallBack to the RecommendationService inproc microservice
public class RecommendationService {
public void recommend(final Callback<List<Recommendation>> recommendationsCallback,
final String userName) {
Now we are taking a callback and we can decide when we want to handle this recommendation generation request. We can do it right away if there user data we need is in-memory or we can delay it.
If the user is found, call the callback right away for RecommendationService inproc microservice
public void recommend(final Callback<List<Recommendation>> recommendationsCallback,
final String userName) {
/** Look for user in user cache. */
User user = users.get(userName);
/** If the user not found, load the user from the user service. */
if (user == null) {
...
} else {
/* Call the callback now because we can handle the callback now. */
recommendationsCallback.accept(runRulesEngineAgainstUser(user));
}
}
Notice, if the user is found in the cache, we run our recommendation rules in-memory and call the callback right away
recommendationsCallback.accept(runRulesEngineAgainstUser(user)).
The interesting part is what do we do if don't have the user loaded.
If the user was not found, load him from the user microservice, but still don't block
public void recommend(final Callback<List<Recommendation>> recommendationsCallback,
final String userName) {
/** Look for user in users cache. */
User user = users.get(userName);
/** If the user not found, load the user from the user service. */
if (user == null) {
/* Load user using Callback. */
userDataService.loadUser(new Callback<User>() {
@Override
public void accept(final User loadedUser) {
handleLoadFromUserDataService(loadedUser,
recommendationsCallback);
}
}, userName);
}
...
Here we use a CallBack to load the user, and when the user is loaded, we call
handleLoadFromUserDataService which adds some management about handling the callback so we can still handle this call, just not now.Lambda version of last example
public void recommend(final Callback<List<Recommendation>> recommendationsCallback,
final String userName) {
/** Look for user in users cache. */
User user = users.get(userName);
/** If the user not found, load the user from the user service. */
if (user == null) {
/* Load user using lambda expression. */
userDataService.loadUser(
loadedUser -> {
handleLoadFromUserDataService(loadedUser,
recommendationsCallback);
}, userName);
}
...
Using lambdas like this makes the code more readable and terse, but remember don't deeply nest lambda expressions or you will create a code maintenance nightmare. Use them judiciously.
Queue Callbacks - Doing something later
What we want is to handle the request for recommendations after the user service system loads the user from its store.
Handling UserServiceData callback methods once we get them.
public class RecommendationService {
private final SimpleCache<String, User> users =
new SimpleCache<>(10_000);
private UserDataServiceClient userDataService;
private BlockingQueue<Runnable> callbacks =
new ArrayBlockingQueue<Runnable>(10_000);
...
public void recommend(final Callback<List<Recommendation>> recommendationsCallback,
final String userName) {
...
}
/** Handle defered recommendations based on user loads. */
private void handleLoadFromUserDataService(final User loadedUser,
final Callback<List<Recommendation>> recommendationsCallback) {
/** Add a runnable to the callbacks queue. */
callbacks.add(new Runnable() {
@Override
public void run() {
List<Recommendation> recommendations = runRulesEngineAgainstUser(loadedUser);
recommendationsCallback.accept(recommendations);
}
});
}
handleLoadFromUserDataService rewritten using Lambda
public class RecommendationService {
...
/** Handle defered recommendations based on user loads. */
private void handleLoadFromUserDataService(final User loadedUser,
final Callback<List<Recommendation>> recommendationsCallback) {
/** Add a runnable to the callbacks list. */
callbacks.add(() -> {
List<Recommendation> recommendations = runRulesEngineAgainstUser(loadedUser);
recommendationsCallback.accept(recommendations);
});
}
The important part there is that every time we get a callback call from
UserDataService, we then perform our CPU intensive recommendation rules and callback our caller. Well not exactly, what we do is enqueue an runnable onto our callbacks queue, and later we will iterate through those but when?Queue Callbacks Handling callbacks when our receive queue is empty, a new batch started or we hit a batch limit
The
RecommendationService can be notified when its queue is empty, it has started a new batch and when it has reached a batch limit. These are all good times to handle callbacks from the UserDataService.Draining our callback queue
@QueueCallback({
QueueCallbackType.EMPTY,
QueueCallbackType.START_BATCH,
QueueCallbackType.LIMIT})
private void handleCallbacks() {
flushServiceProxy(userDataService);
Runnable runnable = callbacks.poll();
while (runnable != null) {
runnable.run();
runnable = callbacks.poll();
}
}
It is important to remember when handling callbacks from another microservice that you want to handle callbacks from the other service before you handle more incomming requests from you clients. Essentially you have clients that have been waiting (async waiting but still), and these clients might represent an open TCP/IP connection like an HTTP call so it is best to close them out before handling more requests and like we said they were already waiting around with an open connection for users to load form the user service.
To learn more about CallBacks, plesae read QBit Java MicroService Lib CallBack fundamentals.
Workers - pools and shards
public class ServiceWorkers {
public static RoundRobinServiceDispatcher workers() {...
public static ShardedMethodDispatcher shardedWorkers(final ShardRule shardRule) {...
You can compose sharded workers (for in-memory, thread safe, CPU intensive services), or workers for IO or talking to foreign services or foreign buses.
Here is an example that uses a worker pool with three service workers in it:
Let's say you have a service that does something:
//Your POJO
public class MultiWorker {
void doSomeWork(...) {
...
}
}
Now this does some sort of IO and you want to have a bank of these running not just one so you can do IO in parallel. After some performance testing, you found out that three is the magic number.
You want to use your API for accessing this service:
public interface MultiWorkerClient {
void doSomeWork(...);
}
Now let's create a bank of these and use it.
First create the QBit services which add the thread/queue/microbatch.
/* Create a service builder. */
final ServiceBuilder serviceBuilder = serviceBuilder();
/* Create some qbit services. */
final Service service1 = serviceBuilder.setServiceObject(new MultiWorker()).build();
final Service service2 = serviceBuilder.setServiceObject(new MultiWorker()).build();
final Service service3 = serviceBuilder.setServiceObject(new MultiWorker()).build();
Now add them to a ServiceWorkers object.
ServiceWorkers dispatcher;
dispatcher = workers(); //Create a round robin service dispatcher
dispatcher.addServices(service1, service2, service3);
dispatcher.start(); // start up the workers
You can add services, POJOs and method consumers, method dispatchers to a service bundle. The service bundle is an integration point into QBit.
Let's add our new Service workers. ServiceWorkers is a ServiceMethodDispatcher.
/* Add the dispatcher to a service bundle. */
bundle = serviceBundleBuilder().setAddress("/root").build();
bundle.addServiceConsumer("/workers", dispatcher);
bundle.start();
We are probably going to add a helper method to the service bundle so most of this can happen in a single call.
Now you can start using your workers.
/* Start using the workers. */
final MultiWorkerClient worker = bundle.createLocalProxy(MultiWorkerClient.class, "/workers");
Now you could use Spring or Guice to configure the builders and the service bundle. But you can just do it like the above which is good for testing and understanding QBit internals.
QBit also supports the concept of sharded services which is good for sharding resources like CPU (run a rules engine on each CPU core for a user recommendation engine).
QBit does not know how to shard your services, you have to give it a hint. You do this through a shard rule.
public interface ShardRule {
int shard(String methodName, Object[] args, int numWorkers);
}
We worked on an app where the first argument to the services was the username, and then we used that to shard calls to a CPU intensive in-memory rules engine. This technique works. :)
The ServiceWorkers class has a method for creating a sharded worker pool.
public static ShardedMethodDispatcher shardedWorkers(final ShardRule shardRule) {
...
}
To use you just pass a shard key when you create the service workers.
dispatcher = shardedWorkers((methodName, methodArgs, numWorkers) -> {
String userName = methodArgs[0].toString();
int shardKey = userName.hashCode() % numWorkers;
return shardKey;
});
Then add your services to the ServiceWorkers composition.
int workerCount = Runtime.getRuntime().availableProcessors();
for (int index = 0; index < workerCount; index++) {
final Service service = serviceBuilder
.setServiceObject(new ContentRulesEngine()).build();
dispatcher.addServices(service);
}
Then add it to the service bundle as before.
dispatcher.start();
bundle = serviceBundleBuilder().setAddress("/root").build();
bundle.addServiceConsumer("/workers", dispatcher);
bundle.start();
Then just use it:
final MultiWorkerClient worker = bundle.createLocalProxy(MultiWorkerClient.class, "/workers");
for (int index = 0; index < 100; index++) {
String userName = "rickhigh" + index;
worker.pickSuggestions(userName);
}
Built in shard rules
public class ServiceWorkers {
...
public static ShardedMethodDispatcher shardOnFirstArgumentWorkers() {
...
}
...
public static ShardedMethodDispatcher shardOnFifthArgumentWorkers() {
...
}
public static ShardedMethodDispatcher shardOnBeanPath(final String beanPath) {
...
}
The shardOnBeanPath allows you to create a complex bean path navigation call and use its property to shard on.
/* shard on 2nd arg which is an employee
Use the employees department's id property. */
dispatcher = shardOnBeanPath("[1].department.id");
/* Same as above. */
dispatcher = shardOnBeanPath("1/department/id");
You can find a lot more in the wiki. Also follow the commits. We have been busy beavers. QBit the microservice lib for Java - JSON, REST, WebSocket.
No comments:
Post a Comment